
征程 6|部署模型尾部 conv 输出 type/layout/scale 解读
本文使用 pytorch 框架,以 conv 为例,介绍如何同时满足 conv int32 + NCHW/NHWC 这两种情况。另外,专开一个章节介绍 scale 为 1 的原因。
1. 引言
在算法模型部署阶段,大家可能会遇到这三个问题:
- 为了保证精度,模型尾部 conv/linear 需要是 int32 输出
- 为了适配后处理代码,模型尾部 conv/linear 输出 layout 有时是 NCHW 的,有时是 NHWC 的
- 为什么 conv/linear 输出的 scale 会是 1?这符合预期吗?
本文使用 pytorch 框架,以 conv 为例,介绍如何同时满足 conv int32 + NCHW/NHWC 这两种情况。另外,专开一个章节介绍 scale 为 1 的原因。
2. 输出类型/layout 解读
2.1 Conv int32 + NCHW
从一个基础示例看 conv 输出类型与 layout:
class SmallModel(nn.Module):
def __init__(self):
super(SmallModel, self).__init__()
self.quant = QuantStub()
self.dequant = DeQuantStub()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=256, kernel_size=1)
self.batchnorm = nn.BatchNorm2d(256)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=256, out_channels=60, kernel_size=1)
def forward(self, x):
x = self.quant(x)
x = self.conv1(x)
x = self.batchnorm(x)
x = self.relu(x)
x = self.conv2(x)
x = self.dequant(x)
return x
example_input = torch.randn(8, 1, 1, 160)
model = SmallModel()
output = model(example_input)
进行工具链量化转换后,输出 conv 情况如下图:
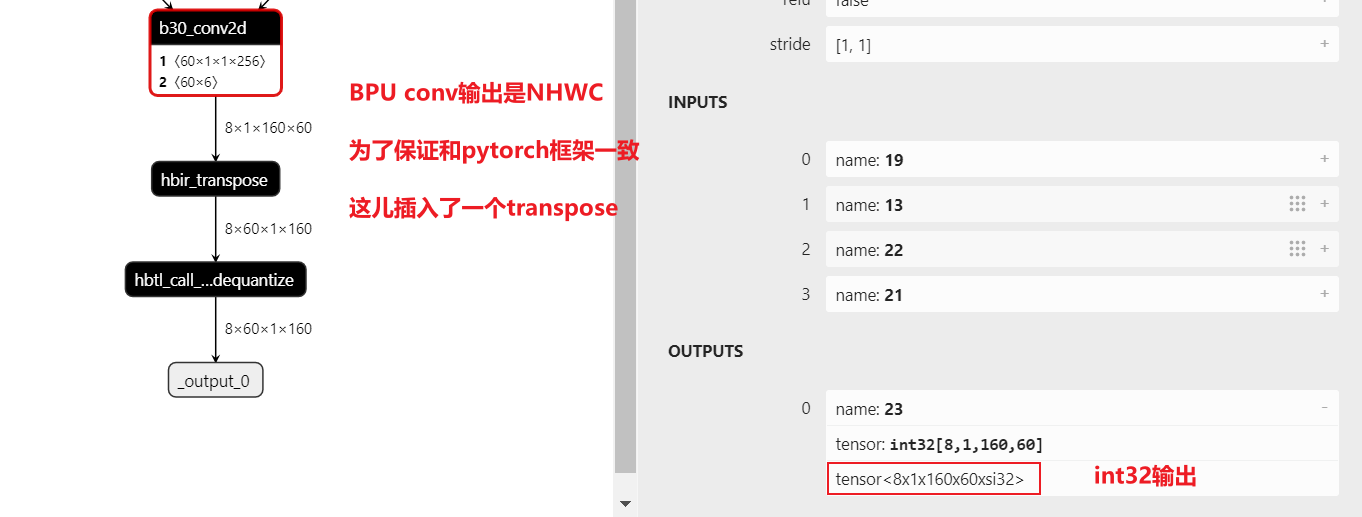
BPU conv 输出默认是 NHWC 的,由于 pytorch 框架输出是 NCHW 的,所以工具会在模型尾部自动加一个 transpose 来保证 layout 一致。此时,模型尾部 conv 输出也是 int32 的,符合 conv int32 + NCHW 预期。
2.2 Conv int32 + NHWC
- 错误示范
class SmallModel(nn.Module):
def __init__(self):
super(SmallModel, self).__init__()
self.quant = QuantStub()
self.dequant = DeQuantStub()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=256, kernel_size=1)
self.batchnorm = nn.BatchNorm2d(256)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=256, out_channels=60, kernel_size=1)
def forward(self, x):
x = self.quant(x)
x = self.conv1(x)
x = self.batchnorm(x)
x = self.relu(x)
x = self.conv2(x)
x = x.permute(0,2,3,1)
x = self.dequant(x)
return x
example_input = torch.randn(8, 1, 1, 160)
model = SmallModel()
output = model(example_input)
进行工具链量化转换后,输出 conv 情况如下图:

尾部 conv 输出 layout 符合预期。
尾部 conv 输出 int16,不符合预期。原因是:在模型中,只有 conv 与 dequant 直接相连,conv 才会是 int32。
怎么实现 conv int32 + NHWC 输出呢?
- 正确示范
class SmallModel(nn.Module):
def __init__(self):
super(SmallModel, self).__init__()
self.quant = QuantStub()
self.dequant = DeQuantStub()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=256, kernel_size=1)
self.batchnorm = nn.BatchNorm2d(256)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=256, out_channels=60, kernel_size=1)
def forward(self, x):
x = self.quant(x)
x = self.conv1(x)
x = self.batchnorm(x)
x = self.relu(x)
x = self.conv2(x)
x = self.dequant(x)
x = x.permute(0,2,3,1)
return x
example_input = torch.randn(8, 1, 1, 160)
model = SmallModel()
output = model(example_input)
在 dequant 后面加 permute 即可实现 conv int32 + NHWC 输出。

3. 什么时候 scale 为 1
在第 2 节中的示例,正常走工具链搭建 QAT 的流程,一般情况下,都不会出现 scale 为 1 的情况,如下图示例:箭头指向的位置都是 scale 的数值。
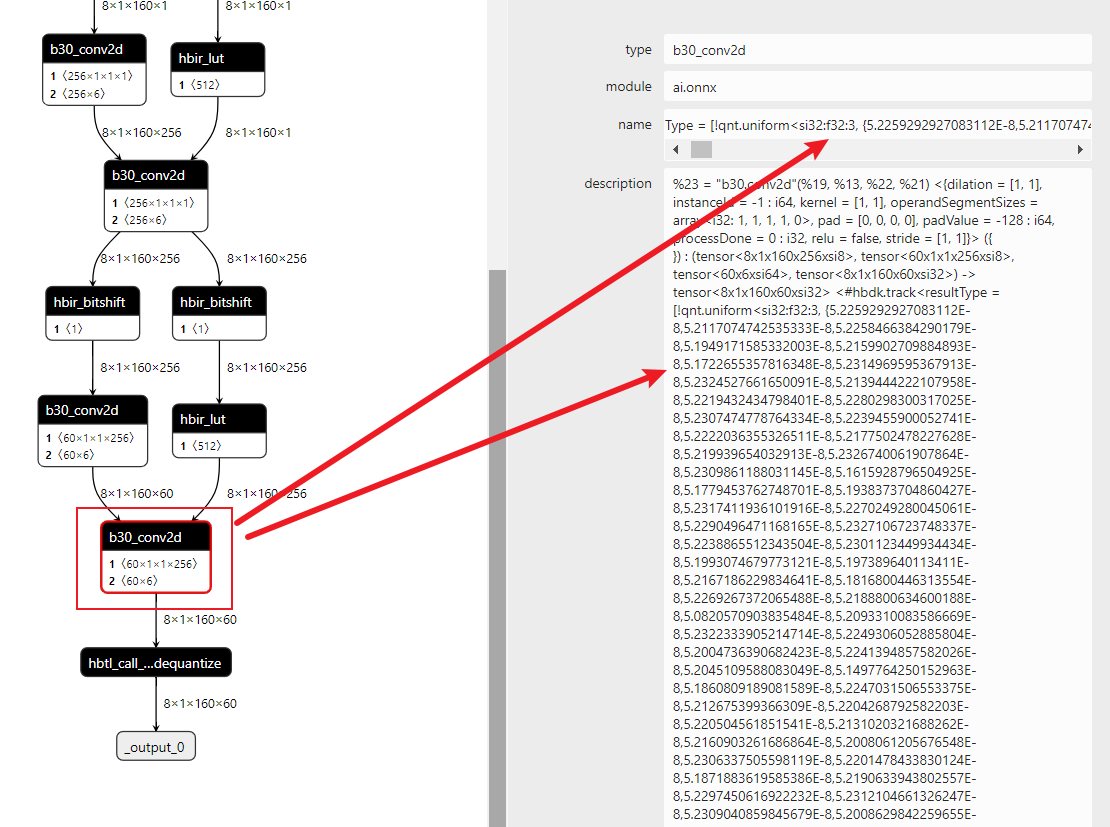
什么时候 scale 会是 1 呢?首先要来了解 scale=1 是在什么时候生成的:在 prepare 初始化模型的时候,scale 为 1,举个例子,看 scale 的变化
calib_model = prepare(model.eval(), example_input, calibration_8bit_weight_16bit_act_qconfig_setter)
print("calib_model:", calib_model) # scale均为1
calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.CALIBRATION)
print("calib_model:", calib_model) # scale均为1
calib_model(example_input)
calib_model.eval()
print("calib_model:", calib_model) # scale不为1
set_fake_quantize(calib_model, FakeQuantState.VALIDATION)
calib_out = calib_model(example_input)
print("calib_model:", calib_model) # scale不为1
qat_bc = export(calib_model, example_input)
根据上述代码,沿着这个线索来分析 scale 为 1 的可能原因。
- 没校准,直接 export 导出 bc 文件
- 在进行模型编译时,采用 prepare 后加载权重的方式,若权重中的 scale 为 1,则编译时 scale 也为 1
- 在进行模型编译时,采用 prepare 后加载权重的方式,加载权重时,部分位置的权重没加载进去,这部分 scale 就会是 1
scale 为 1 一定就是错的吗?其实不一定,只能说大部分是错的。判断 scale=1 正确与否,跑一下模型推理,看结果是否正确即可~
4. 典型问题
问题描述:qat 模型精度正常,export 后的 qat.bc 精度不正常,且在 convert+compile 后发现,部分 conv 输出 scale 为 1,量化类型为 int16。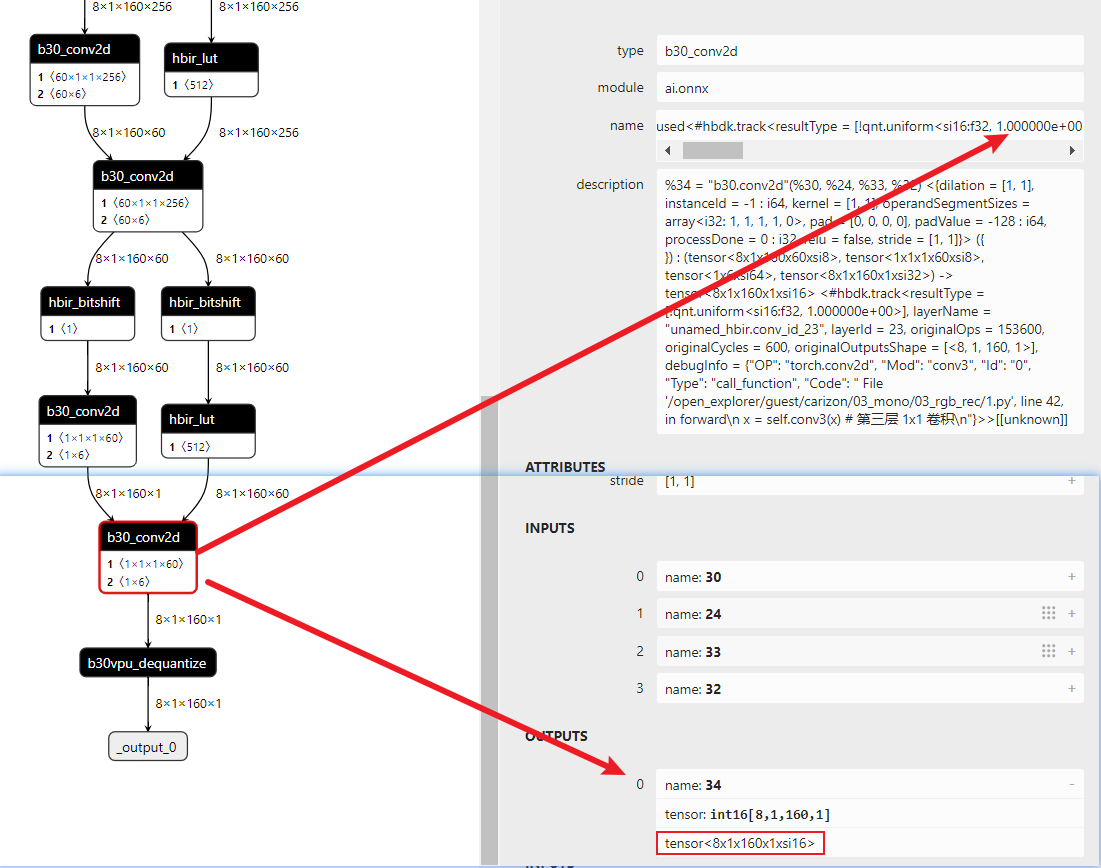
最终原因:训练 qat 结束保存权重时,网络某输出结构为:
x = self.conv2(x)
x = self.dequant(x)
为了适配板端部署 layout 要求,直接修改该输出结构为:
x = self.conv2(x)
x = x.permute(0,2,3,1)
x = self.dequant(x)
x)
x = self.dequant(x)
为了适配板端部署 layout 要求,直接修改该输出结构为:
```Plain
x = self.conv2(x)
x = x.permute(0,2,3,1)
x = self.dequant(x)
并加载了之前训练的权重,且未关注 miss key/unexpected key,此时会出现部分 conv 输出 scale 为 1,量化类型为 int16 的问题。

加入社区
更多推荐



 21
21 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)