
【智驾中的大模型 -3】VLA 在自动驾驶中的应用
在上一篇文章中,我们深入探讨了 VLM 模型在自动驾驶中的应用。今天,我们就来全面介绍一下 VLA 模型在自动驾驶中的具体应用。
1.前言
在上一篇文章中,我们深入探讨了 VLM 模型在自动驾驶中的应用。VLA(Very Large Architecture,大型架构)和 VLM(Very Large Model,非常大模型)在 AI 领域皆指向超大规模的神经网络模型,然而,它们的侧重点存在显著差异。VLA 端到端特指融合视觉、语言和动作这三种能力的端到端自动驾驶架构。细致来讲,它是一种前沿的多模态机器学习模型,致力于达成从感知输入径直映射到机器人或汽车控制动作的完备闭环。
今天,我们就来全面介绍一下 VLA 模型在自动驾驶中的具体应用。
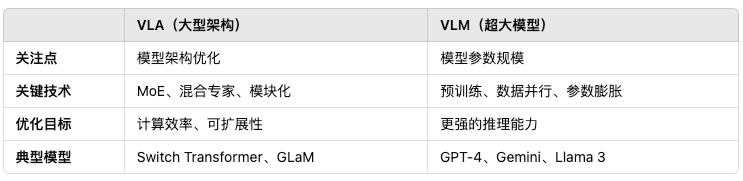
2.VLA 与 VLM 的区别
VLA 强调的是 模型的架构设计,指的是超大规模的深度学习模型架构,通常涉及以下特征:
- 创新的网络结构:如 Mixture of Experts(MoE)、稀疏激活 Transformer、多模态融合等架构优化技术。
- 模块化设计:VLA 可能采用多个子模型(如 MoE)或层次化结构,以提高效率和可扩展性。
- 分布式训练优化:大规模架构需要高效的并行计算和内存优化,如流水线并行、张量并行等。
示例:
- Google 的 Switch Transformer(采用 MoE 架构,部分专家激活,提高计算效率)
- DeepMind 的 GLaM(Gated MoE 架构,可扩展计算)
VLM 更关注 模型参数规模,通常指参数量达到百亿、千亿甚至万亿级别的 AI 模型。这类模型的特点包括:
- 大规模参数:模型参数量极大,如 GPT-4(数万亿参数)或 Gemini-1.5(多万亿参数)。
- 大数据训练:VLM 需要使用全球范围的大规模文本、图像、音频等数据进行训练。
- 高计算需求:训练 VLM 需要超大计算集群(TPU/GPU),且推理时也需要高算力支持。
示例:
- GPT-4( OpenAI)
- Gemini 1.5( Google DeepMind)
- Llama 3( Meta)
核心区别总结:
3.VLA 的核心技术
VLA(Very Large Architecture,大型架构)的核心技术主要围绕高效扩展、计算优化和智能推理,以支持超大规模 AI 模型(如 GPT-4、Gemini、Claude)在训练和推理时的高效计算。
3.1 Mixture of Experts(MoE,混合专家)
Mixture of Experts(MoE,混合专家)是一种神经网络架构**,通过多个**专家网络(Experts)协作完成任务,并由一个门控网络(Gating Network)决定激活哪些专家,从而提高计算效率和泛化能力。MoE 的关键特性是稀疏激活(Sparse Activation)——每次推理或训练时,只使用部分专家,而不是整个模型,从而减少计算开销。
MoE 由三部分组成:
- 输入层(Input Layer):接受输入数据,如文本、图像、语音等。
- 专家网络(Experts):多个子网络,每个专家专注于不同的数据特征。
- 门控网络(Gating Network):用于选择最适合当前输入的专家,并分配计算权重。
对于输入 x,MoE 的输出可以表示为:
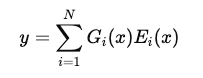
3.1.1 门控策略(Gating Strategies)
门控网络用于选择合适的专家,常见方法包括:
- Softmax 门控:对所有专家计算得分,并通过 softmax 归一化。
- Top-k 门控:仅选择得分最高的 kkk 个专家进行计算(常见于 Switch Transformer)。
- Gated MoE(门控 MoE):使用可训练的门控层,如 GLaM 采用的 gated attention。
3.1.2 稀疏计算(Sparse Computation)
MoE 通过稀疏激活减少计算量,关键方法有:
- Top-k 选择:仅激活部分专家(如 2-4 个),避免所有专家计算,提高效率。
- 负载均衡(Load Balancing):确保不同专家被均匀使用,避免计算不均衡。
3.1.3 训练优化
MoE 由于稀疏性,训练时存在负载不均衡问题,优化策略包括:
- Auxiliary Loss:额外损失项,确保专家负载均衡。
- Routing Regularization:避免部分专家被过度使用,提高泛化能力。
- 数据并行 + 模型并行结合:适配大规模训练框架,如 Tensor Parallelism。
3.1.4 MoE 的优势:
- 计算高效:仅激活部分专家,减少计算需求,相比全参数模型更节省算力。
- 可扩展性强:可以轻松增加专家数量,而不会显著增加计算开销。
- 泛化能力好:不同专家学习不同特征,提高模型适应性。
- 更强性能:MoE 在多个任务上超越传统 Transformer,如 NLP、CV 等领域。
- 示例:
- Switch Transformer(Google):激活少量专家,提高计算效率
- GLaM(Gated MoE)(DeepMind):智能选择专家,提高推理质量
3.2 分布式并行计算(Distributed Parallelism)
分布式并行计算是指在多个计算设备(如 GPU、TPU 或 CPU 集群)上并行执行 AI 模型的训练或推理,以加速计算并支持超大规模模型。
在深度学习中,大规模模型(如 GPT-4、Gemini-1.5、Llama 3)参数量可达数千亿或万亿级,单台计算设备的显存(VRAM)和计算能力无法承载,因此需要分布式并行计算来高效利用计算资源。
分布式计算可以分为数据并行(Data Parallelism, DP)、模型并行(Model Parallelism, MP)和流水线并行(PipelineParallelism, PP)等,此外还有一些混合方法,如 ZeRO 优化。
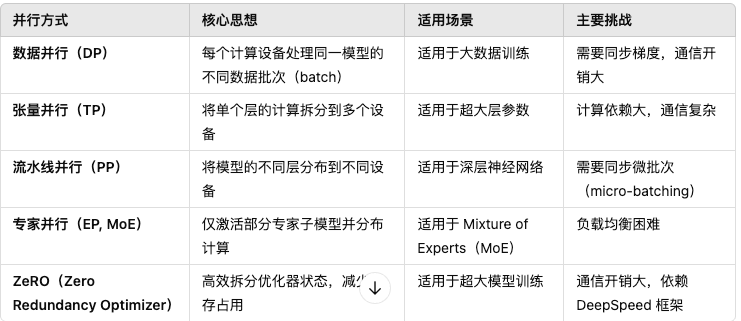
3.2.1 数据并行(Data Parallelism, DP)
核心思想:每个计算设备(GPU/TPU)持有完整的模型副本,但处理不同的数据子集,然后聚合梯度更新参数。
工作流程:
- 每个设备接收不同的数据批次(batch)。
- 计算损失(loss)并计算梯度(gradients)。
- 通过全局梯度同步(AllReduce),计算所有设备的平均梯度。
- 更新模型参数,并同步到所有设备。
优点: 易于实现,框架(如 PyTorch DDP, TensorFlow MirroredStrategy)提供支持。 适用于大数据集训练,不需要拆分模型结构。
缺点: 通信开销大:每次梯度同步需要大量 GPU 间通信,影响扩展性。 显存压力大:每个设备都存完整模型,不能训练超大模型。
优化方法:
- 梯度压缩(Gradient Compression):减少梯度传输的数据量。
- FSDP(Fully Sharded Data Parallel):优化 DP,使其占用更少的显存。
3.2.2 张量并行(Tensor Parallelism, TP)
核心思想:将单个神经网络层的计算拆分到多个设备上,每个设备只计算部分矩阵运算,并进行通信交换数据。
适用于:超大层参数的模型(如 GPT-4、BERT-Large)。
优点: 减少显存占用**,可以训练更大模型。 **减少计算负载,分摊矩阵计算到多个 GPU。
缺点: 通信开销大,多个 GPU 需要频繁交换数据。 适用于特定层结构,不如 DP 泛用性强。
优化方法:
- Megatron-LM:优化 TP 并减少 GPU 之间的通信成本。
- NVIDIA NCCL:用于高效 GPU 间数据交换。
3.2.3 流水线并行(Pipeline Parallelism, PP)
核心思想:将模型的不同层放到不同的设备上,每个设备计算一部分前向和反向传播,形成流水线执行。
适用于:超深层神经网络(如 1000 层 Transformer)。
工作流程:
- 第一个 GPU 计算前几层,并将中间结果传递给下一个 GPU。
- 依次向下传递,直到最后一层计算完毕。
- 反向传播按照相反顺序执行,计算梯度更新。
优点: 减少显存占用**,适用于深层网络。 **更好的计算利用率,减少空闲 GPU 资源。
缺点: 微批次(Micro-batch)问题:必须拆分数据为多个微批次,否则流水线无法充分利用计算资源。 同步问题:不同 GPU 计算速度不同,可能导致计算空转(bubble)。
优化方法:
- GPipe(Google):优化流水线执行,提高吞吐量。
- 1F1B(1 Forward, 1 Backward)策略:减少流水线空转,提高计算效率。
3.2.4 专家并行(Expert Parallelism, MoE)**
核心思想:使用 Mixture of Experts (MoE),让不同 GPU 计算不同的专家网络,只激活部分专家,减少计算负担。
适用于:超大规模 MoE 模型(如 Switch Transformer, GLaM)。
优点: 计算高效,只计算部分专家,减少计算冗余。 适用于 MoE 结构,扩展性强。
缺点: 负载均衡难,部分专家可能被过度使用,影响训练效率。 需要高效的专家分配策略(如 Softmax 门控)。
3.2.5 ZeRO( Zero Redundancy Optimizer)
ZeRO 是 DeepSpeed 提出的优化方法,减少显存占用,使得超大规模模型训练变得可能。
ZeRO 主要包含 3 个阶段:
ZeRO-1:分片优化器状态(Optimizer State Sharding)
ZeRO-2:分片优化器状态 + 梯度(Gradient Sharding)
ZeRO-3:分片优化器状态 + 梯度 + 参数(Parameter Sharding)
优点: 显存占用更低,可以训练 10 倍以上参数 的模型。 适用于超大模型,如 GPT-4、Gemini-1.5。
缺点: 通信开销高,需要高效 GPU 间互联(如 InfiniBand)。
3.3 自监督学习 & 高效训练优化
自监督学习(SSL)是一种无监督学习****方法,模型通过自身生成的伪标签进行训练,无需人工标注数据。SSL 已成为 NLP、CV 以及多模态 AI 领域的核心技术,如 GPT-4、BERT、SimCLR、DINO 等模型都采用了自监督学习进行预训练。
- 自监督学习(Self-Supervised Learning,SSL):VLA 依赖大规模无标注数据进行自监督预训练,比如 BERT、GPT 使用的 Masked Language Model (MLM) 和 Causal Language Model (CLM)。
- 混合精度训练(Mixed Precision Training):采用 FP16/BF16 训练,减少内存占用,提高训练速度。
3.4 多模态融合(Multimodal Fusion)
VLA 关注如何高效处理和融合不同模态(文本、图像、音频、视频等):
- 视觉-语言模型(VLM):结合 Transformer 和 CNN,支持图片+文本输入,如 CLIP、Gemini。
- 跨模态对齐:使用对比学习(Contrastive Learning)对齐不同模态,如 OpenAI 的 CLIP 通过文本-图像对比学习增强理解能力。
- 端到端多模态训练:同时训练不同模态,减少单独训练的开销,提高一致性。
3.5 强化学习与检索增强(RLHF & RAG)
- 强化学习人类反馈(RLHF):如 ChatGPT 采用 RLHF 调优,提高模型输出的对齐性和安全性。
- 检索增强生成(RAG, Retrieval-Augmented Generation):结合外部数据库(如 Wikipedia、私有知识库)进行增强,使模型具有实时信息访问能力。
4.VLA 的主要结构
VLA(Vision-Language-Action)是一类多模态模型,旨在结合视觉(Vision)、语言(Language)和动作(Action)来进行复杂的任务决策,如机器人控制、交互式 AI 以及智能体决策。
VLA 通过融合视觉感知(图像、视频)、语言理解(自然语言指令)和动作规划(强化学习或控制策略)来实现端到端的智能决策。
VLA 通常由以下四个关键模块组成:
- 视觉编码器(Vision Encoder)
- 语言编码器(Language Encoder)
- 跨模态融合(Multi-Modal Fusion)
- 动作生成(Action Decoder / Policy Module)
4.1 视觉编码器
作用:从图像或视频中提取高层次视觉特征,输入格式可以是 RGB 图像、深度图、点云(Point Cloud)等。
常用架构:
- CNN(ResNet, ConvNeXt):用于低级别视觉特征提取。
- Vision Transformer(ViT, Swin Transformer, BEiT):用于全局视觉理解。
- CLIP Vision Encoder:结合大规模文本-图像数据训练,适用于开放世界感知。
4.2 语言编码器
作用:从自然语言输入(如指令、任务描述)中提取文本表征,通常使用 Transformer 结构。
常用架构:
- BERT / RoBERTa:适用于结构化文本理解。
- T5 / GPT 系列:用于文本生成任务。
- CLIP Text Encoder:跨模态对齐的语言编码器。
4.3 跨模态融合
作用:将视觉和语言特征进行融合,以便模型理解多模态信息。
融合方式:

4.4 动作生成
作用:根据融合的多模态信息生成动作,可以是离散动作(分类)或连续动作(回归)。
常见方法:

4.5 典型 VLA 结构示例
以 SayCan(Google DeepMind) 为例,其结构如下:
- 视觉感知:使用 CLIP 提取环境视觉特征。
- 语言理解:使用 PaLM(大语言模型)解析用户指令。
- 跨模态融合:基于 CLIP 计算任务和环境的匹配度。
- 动作决策:结合强化学习选择最佳机器人行动。
4.6 未来优化方向
- 更高效的视觉-语言对齐(如 Video-Text Pretraining)
- 强化多模态记忆(Memory-Augmented Models)
- 自监督学习提升 VLA 训练效率
- 为例,其结构如下:
- 视觉感知:使用 CLIP 提取环境视觉特征。
- 语言理解:使用 PaLM(大语言模型)解析用户指令。
- 跨模态融合:基于 CLIP 计算任务和环境的匹配度。
- 动作决策:结合强化学习选择最佳机器人行动。
4.6 未来优化方向
- 更高效的视觉-语言对齐(如 Video-Text Pretraining)
- 强化多模态记忆(Memory-Augmented Models)
- 自监督学习提升 VLA 训练效率
- 结合 MoE(Mixture of Experts)提升泛化能力

加入社区
更多推荐



 19
19 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)