
CAMA 以视觉为中心的静态地图元素标注方法
CAMA,即 Consistent and Accurate Map Annotation,是一种以视觉为中心的一致且准确地图标注方法。
CAMA | 以视觉为中心的静态地图元素标注方法
01现有标注方法的局限性
在自动驾驶领域,静态地图元素的精确标注是实现高精度环境感知的关键。然而,现有的公共数据集在一致性和准确性方面存在局限,无法满足日益增长的高精度训练数据需求。

图一展示了 nuScenes 数据集中的默认高清地图无法在一致性和准确性两个方面提供准确信息的示例。一致性强调了 3D 注释和 2D 图像之间的对应关系。例如,在某些区域,高清地图中提供了车辆和自行车道之间的车道分隔线。
同时,实际图像在相应区域没有显示车道标记。几何精度反映在高清地图重新投影到原始图像中。重新投影的道路齿(黄点)与图像中的实际道路齿有偏差。主要原因是数据集提供的高清地图没有高度信息,并且自我姿态相对于地图不准确。
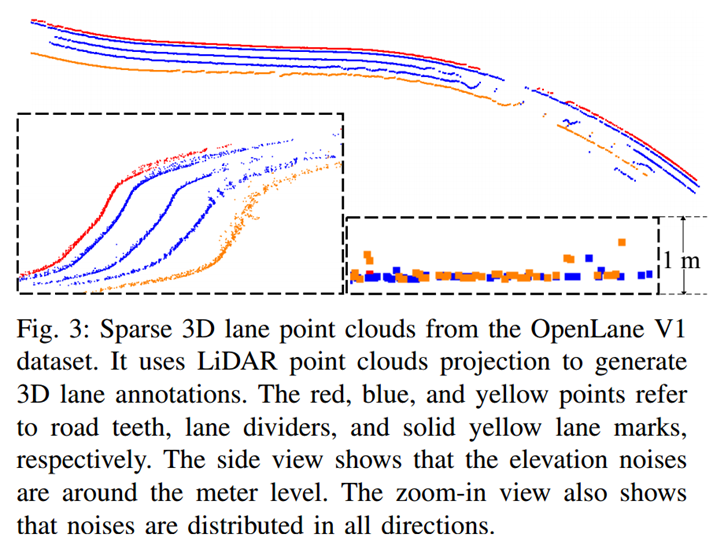
除高精地图外,一些数据集使用 LiDAR 点进行 3D 道路元素标注。这种使用 LiDAR 点投影的 3D 车道注释通常会受到噪声和伪影的影响。图 3 展示了 OpenLane v1 中车道线注释沿高程方向的噪声约为米级。
02 一致、准确的纯视觉标注方法
为了解决这些挑战,文中提出了 CAMA,即 Consistent and Accurate Map Annotation,是一种以视觉为中心的一致且准确地图标注方法。CAMA 无需激光雷达输入,即可生成高质量的 3D 静态地图元素标注,显著提升了重投影精度和时空一致性。
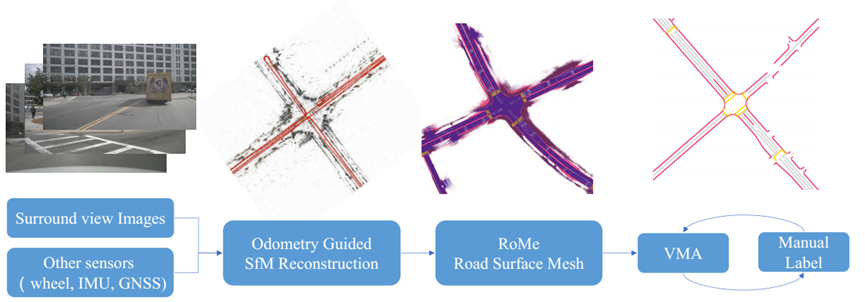
CAMA 系统主要分为两个部分:场景重建和道路元素矢量化标注。
03 场景重建
场景重建主要由 WIGO,SfM 和 RoMe 这三部分组成。
3.1 WIGO
WIGO 算法是一种融合了车轮里程计、惯性测量单元(IMU)和全球导航卫星系统(GNSS)数据的里程计算法。这些传感器数据为车辆提供了一个初始的、粗略的位置和姿态估计,这些估计随后被用于更精细的 3D 重建。
3.2 SfM
CAMA 使用 SfM 进行场景重建,主要对 COLMAP 做了以下五方面改进:
- Initialization:提出了一种用于 SfM 的里程计引导初始化 (Odometry Guided Initialization, OGI)。具体来说,WIGO 姿势被转换为具有外部参数的前置摄像头坐标。给定初始姿势,增量式 SfM 可以用空间引导式 SfM 代替。
- Matching:针对特定驾驶场景提出了单应性引导空间对 (Homograph-guided Spatial Pairs, HSP),利用 WIGO 姿态,可以通过图像之间的视锥重叠来过滤潜在匹配的图像对。此外,对于自动驾驶应用,所有摄像头都具有相对于地面的近似外部特征。可以通过对地面应用单应性变换来进一步过滤图像之间的视觉重叠,以强调道路表面区域的重要性。
- Feature point:在自己数据集上训练一个 Superpoint 特征提取网络,特别关注地面。
- Bundle adjustment:将迭代 BA 策略和 triangulation points filter 相结合。在迭代过程中可以从 SfM 稀疏模型中删除不准确的点。
- Rigid prior:使用刚性 BA 来替代 COLMAP 中的普通 BA 过程。其原理是车辆上的多个摄像头安装在车身上,可以视为安装在刚体上。直接应用刚性 BA 不仅可以提高管道的整体效率,还可以提高鲁棒性。
通过以上改进文中在自动驾驶数据集效率提升了 5 倍和 成功率提升了 20% 。
3.3 RoMe
使用 RoMe 进行路面网格重建,做了以下三方面改进:
- Surface points:使用 MaskFormer 进行语义分割,结合 SfM 模型恢复稀疏语义点云,然后提取路面点云。为了进一步提高 SfM 点过于稀疏时的稳健性,我们还根据自我姿势和摄像机与地面之间的外部因素对其他点进行采样。这种方法提高了路面初始化的整体质量。
- Elevation:利用上一步生成的稀疏路面(3D 点云)训练 MLP 预测路面高度。
- Semantic:将原始图像及其相应的 2D 分割结果作为监督来训练每个网格的语义标签和光度特征。
最终,可以获得高精度的 3D 路面网格。3D 路面网格可以表示为 2D BEV 图像和高度图像,作为地图标注的输入。
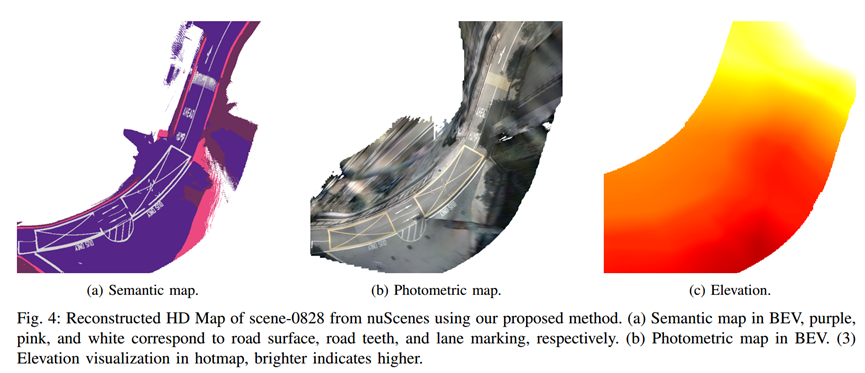
3.4 Map annotation
扩展了 VMA 以进行初始地图注释,使用人在回路方法加快标注效率。VMA 是一个基于 MapTR 的离线地图自动注释框架。输入是串联的 2D BEV 语义光度图像,而输出是道路表面元素(例如车道分隔线、道路齿、人行横道等)的矢量化表示。
文中使用语义图和光度图像作为输入以提高 VMA 推理能力。对于地图元素的标注仍在 2D BEV 空间中。一旦获得 2D 表示,就会组合高度图以将 2D 矢量提升为实际的 3D 道路表面和矢量。
04 标注验证
文中在 nuScenes 数据集上进行了验证生成了优化后的注释,提出了重投影误差指标用于衡量重投影精度:
- Step1: 将 3D 注释向量元素重新投影到每个 2D 图像中
- Step2: 使用现成的 2D 车道实例分割提取图像空间中的所有实例,并为每个实例拟合折线
- Step3: 使用匈牙利算法匹配步骤 1 中的投影元素和步骤 2 中提取的元素
- Step4: 计算每个匹配元素的平均像素距离
CAMA 标注的标注在重投影误差上显著降低
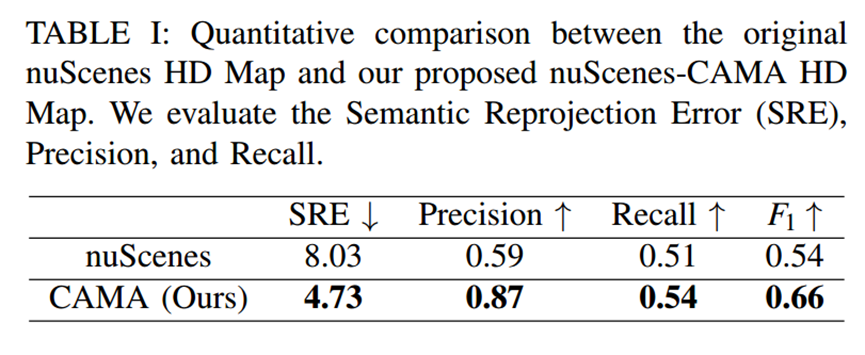
重投影可视化效果对比

05 应用
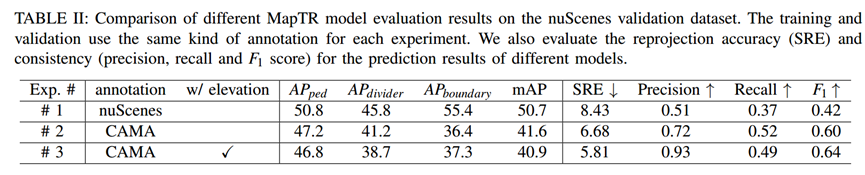
使用 MapTRv2 作为基线模型,不同标注进行训练,重投影精度也得到了提升。
06 总结
文中研究了在线高清地图构建的关键因素,并认为重新投影精度和时空一致性的注释质量对于感知算法训练至关重要。基于这一见解,文中提出了 CAMA,一种以视觉为中心的方法,能够获得一致且准确的静态地图元素注释。

加入社区
更多推荐



 15
15 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)