
【征程 6 工具链性能分析与优化-1】编译器预估 perf 解读与性能分析
这篇文章中,我们将首先介绍layerdetails中的参数信息,然后将结合实例分析如何利用layerdetails来分析模型的性能瓶颈,进而对模型的性能进行优化。
01 引言
本篇文章中,我们将首先介绍 layerdetails 中的参数信息,然后将结合实例分析如何利用 layerdetails 来分析模型的性能瓶颈,进而对模型的性能进行优化。
02 layerdetails 中信息解读
征程 6 工具链目前提供了两种方式生成性能评估报告:
- 使用
hb_compile工具编译模型时会自动生成性能评估报告; - 编译出 hbm 模型后,使用编译器提供的 python API
hbm_perf生成性能评估报告,这里需要注意,调用 compile 接口编译模型时需要开启 debug 后才能生成 layerdetails。
性能预估报告包括 html 和 json 两个版本,通常看 html 即可。
html 中包括 Summary、Temporal Statistics 和 Layer Details 这 3 个部分,下面将逐一介绍。
2.1 Summary
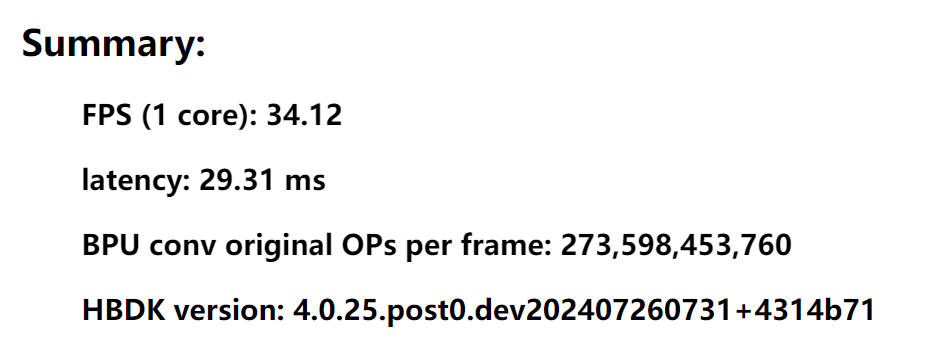
- FPS**( 1 core)**
- 在 1 个 BPU 内核上运行时的估计 FPS。
- Latency
- 编译后的模型推理一次的时间,编译的模型可能包含 batch。
- BPU conv original OPs per frame
- 原始模型卷积层的计算量。卷积变体(deconv、dilated conv、deformable conv 等)也被计算在内。
2.2 Temporal Statistics
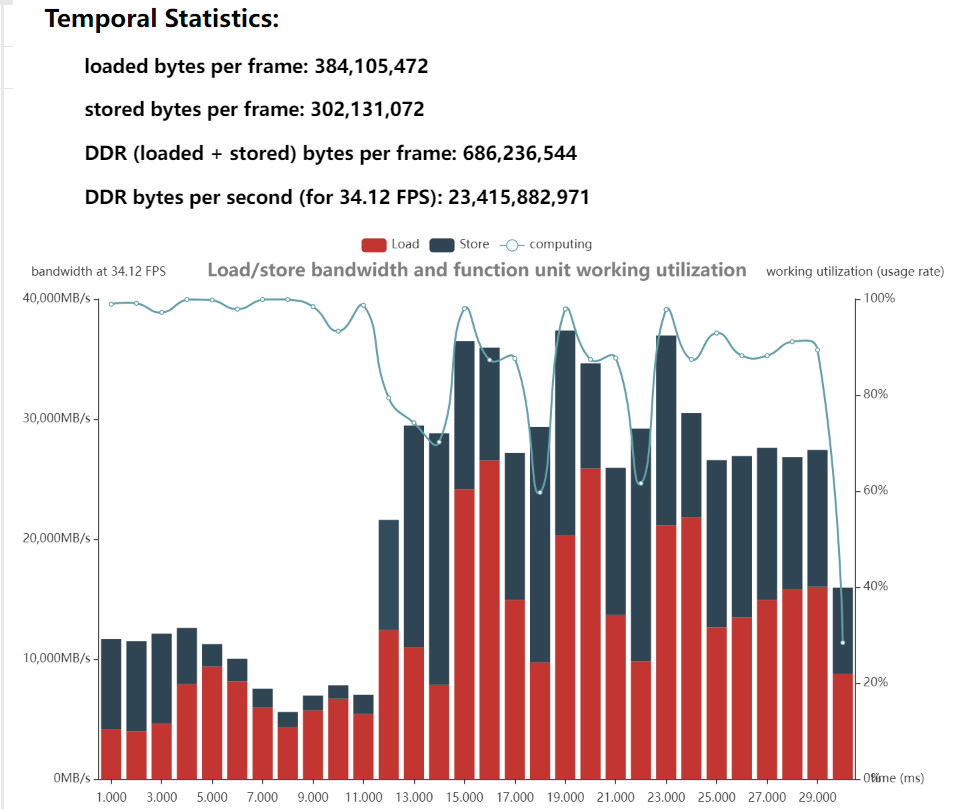
- Loaded bytes per frame
- 每帧推理 BPU 需要读取 DDR 的字节数。(编译时可能有batch,每帧推理不一定等于每次推理)
- Stored bytes per frame
- 每帧推理 BPU 需要写入 DDR 的字节数。(编译时可能有batch,每帧推理不一定等于每次推理)
- DDR (loaded + stored) bytes per frame:
- 每帧推理 BPU 需要读写 DDR 的字节数
- DDR bytes per second (for xxx FPS):
- 每秒BPU需要读写 DDR 的字节数。
2.3 Layer Details
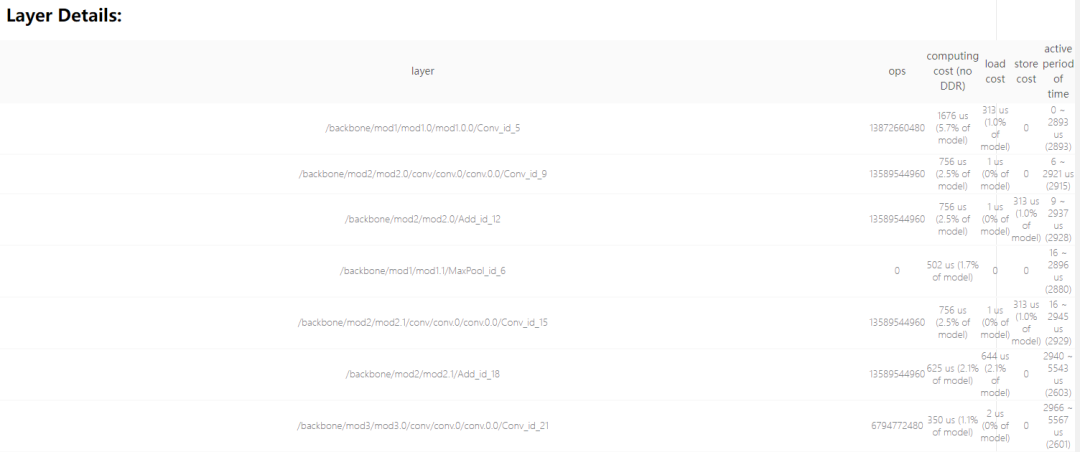
- layer
- 原始模型的 layer name。torch 模型没有 layer name,torch 转 hbir 时会自动命名
- original ops
- 原始 layer 的计算量(包含卷积及其变种)
- computing cost( no DDR**)**
- 编译后 layer 的时间开销,不包括 DDR 相关的时间开销,但会包含 reorder(数据重排)的开销
- load/store cost
- 编译后 layer 的 DDR 访问时间开销。对于非模型输入输出的 feature,DDR 访问可能被优化掉。
- active period of time
- 编译后 layer 活跃时间段。不代表该 layer 的执行时间,通常都是多个 layer 交替/并行执行。
03 性能分析实例
3.1 通用流程
- 首先观察 Temporal Statistics 统计图中的曲线:
- 观察 computing 曲线是否有波动,带宽瓶颈会引起它的波动
- 观察 load&store 柱状图,配合 computing 曲线,判断是否有带宽瓶颈
- 然后根据时态统计图中的时间轴,观察在某区间的 layer detail。
3.2 实例分析
分析过程
1.观察 computing 曲线是否有波动,带宽瓶颈会引起它的波动:
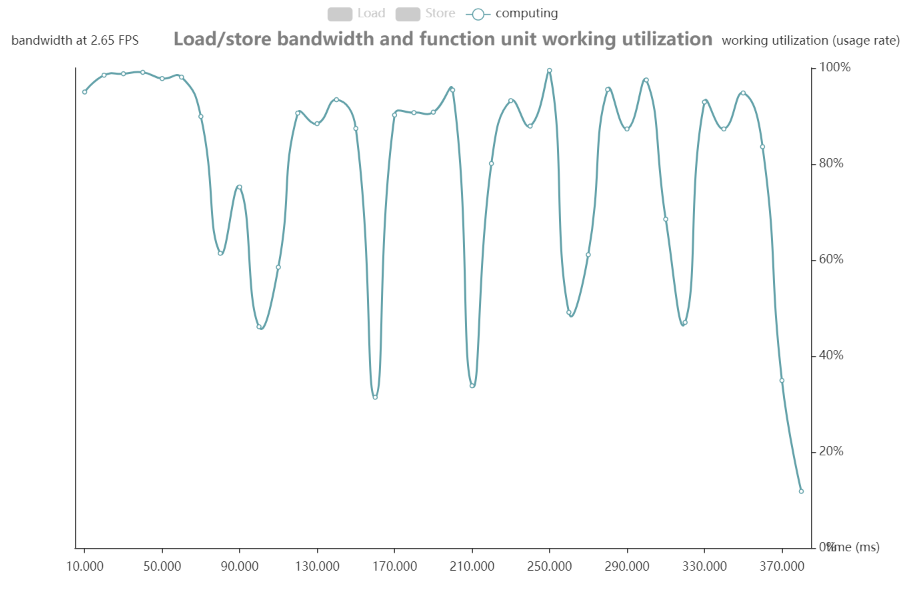
如上图,此模型的 computing 曲线波动较大,模型可能存在带宽瓶颈。
2.进一步观察 load&store 柱状图,并配合 computing 曲线:
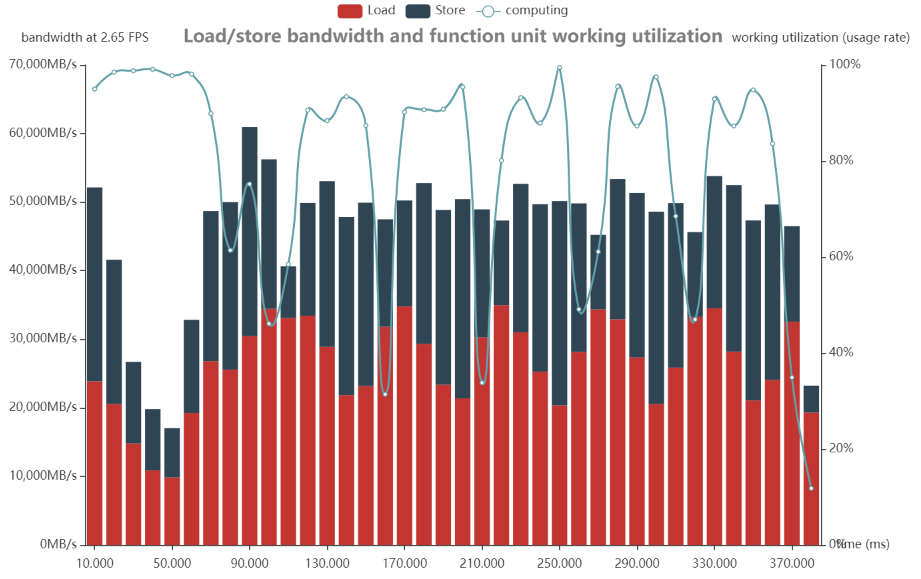
可以看到,图中由多处的 load&store 柱状图高于 computing 曲线,这些地方可能存在了带宽瓶颈。
3.根据时态统计图中的时间轴,观察在某区间的 layer detail:
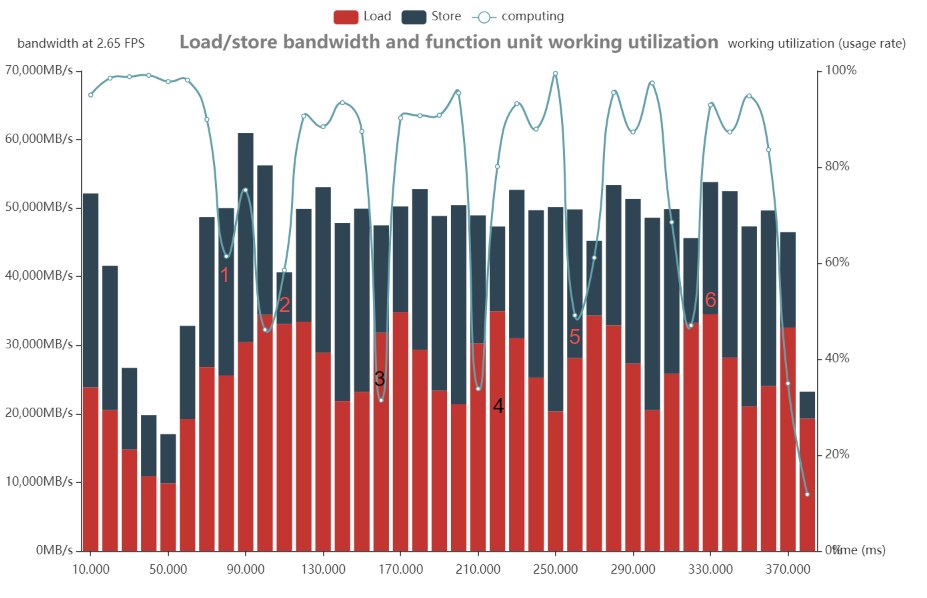
如上图,标记了 6 处 load&store 柱状图高于 computing 的地方,对应的时间为:
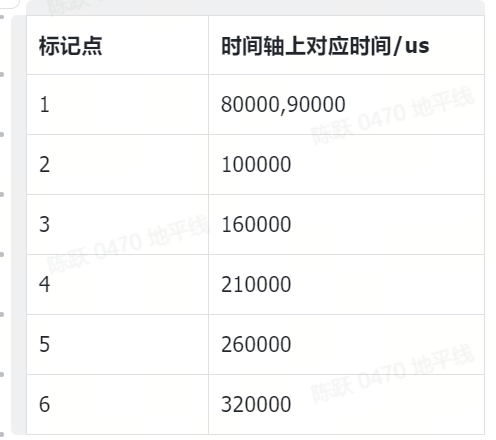
然后根据 layerdetails 的 active period of time 查看以上时间点的对应算子:
- 标记点 1&标记 2
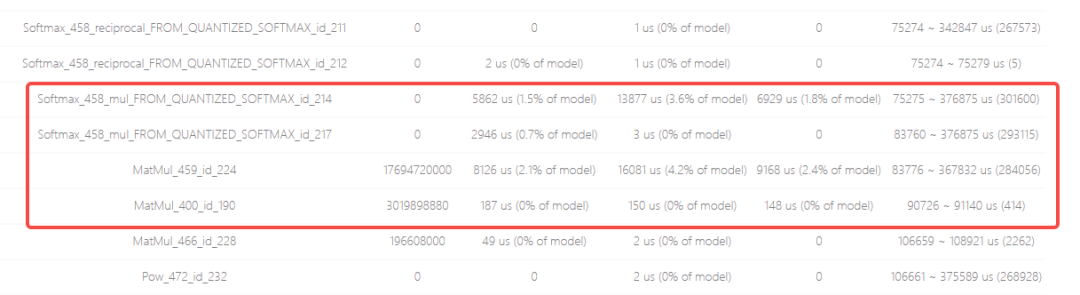
可以看到引起带宽瓶颈的算子的 Softmax_458_mul、MatMul_459,onnx 模型中对应的子结构为:
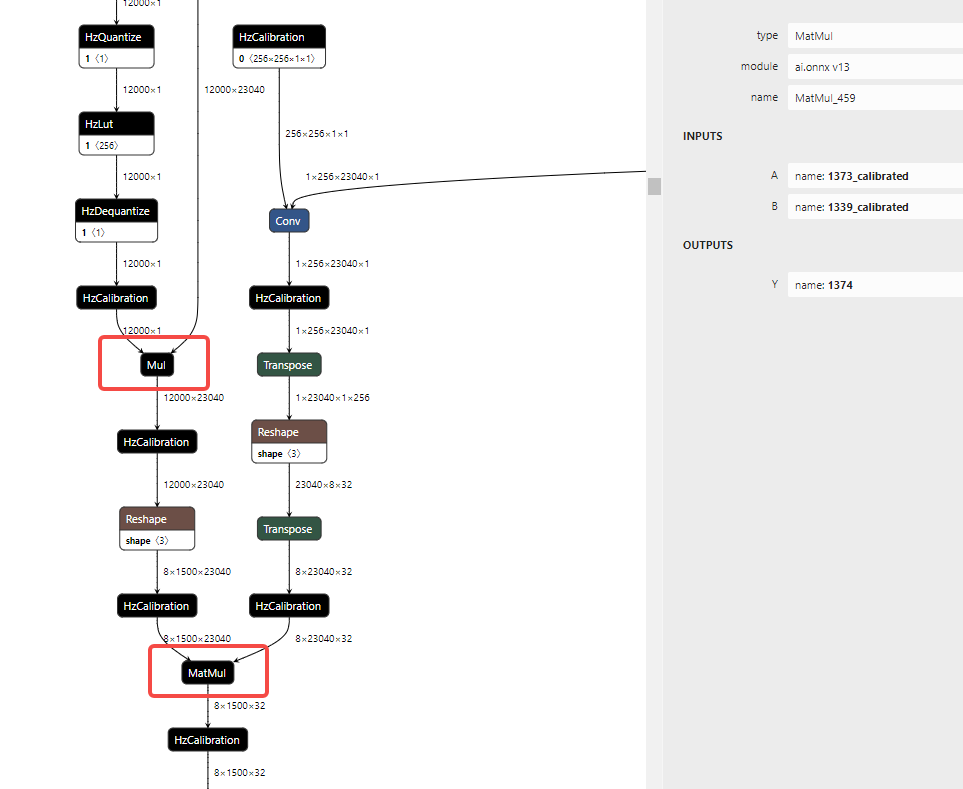
- 标记点 3

可以看到引起带宽瓶颈的算子的 Softmax_765_mul、MatMul_766,onnx 模型中对应的子结构为:
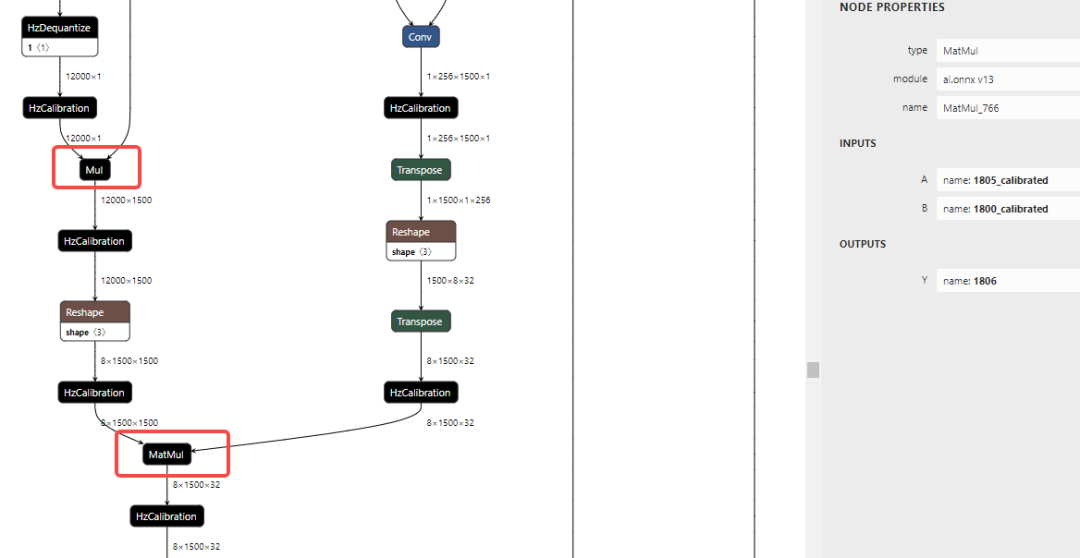
- 标记点 4

可以看到引起带宽瓶颈的算子的 Softmax_968_mul、MatMul_969,onnx 模型中对应的子结构为:
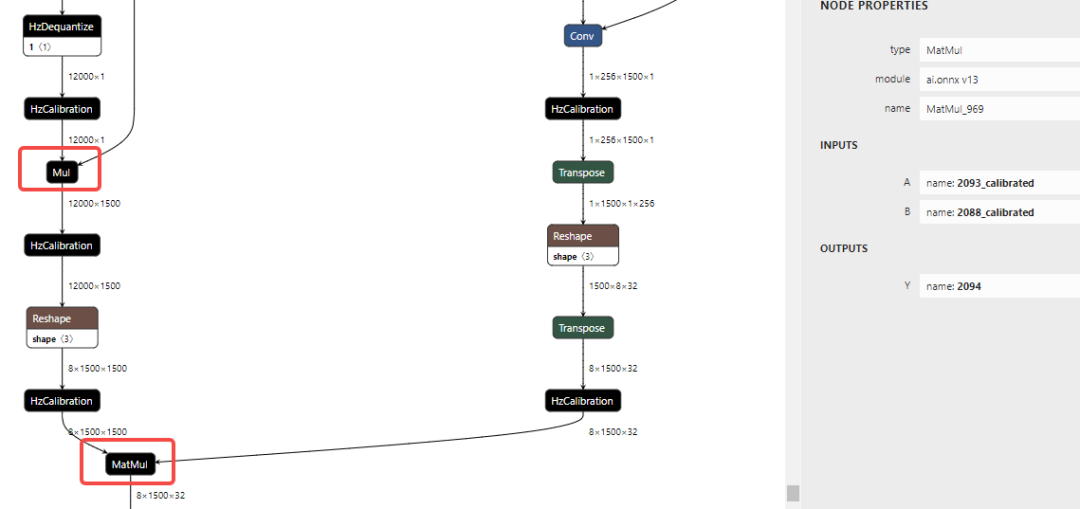
- 标记点 5
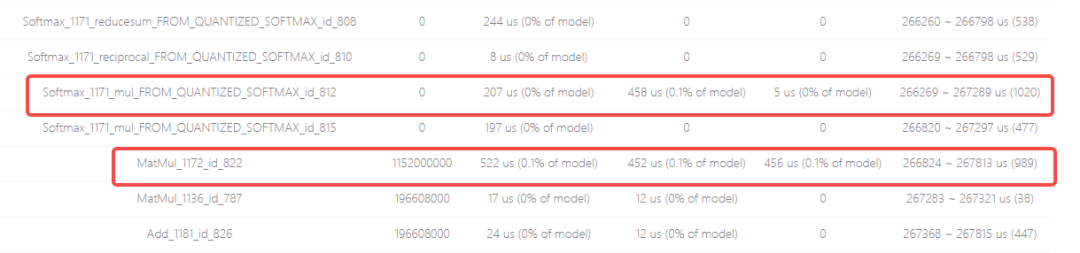
可以看到引起带宽瓶颈的算子的 Softmax_1171、MatMul_1172,onnx 模型中对应的子结构为:
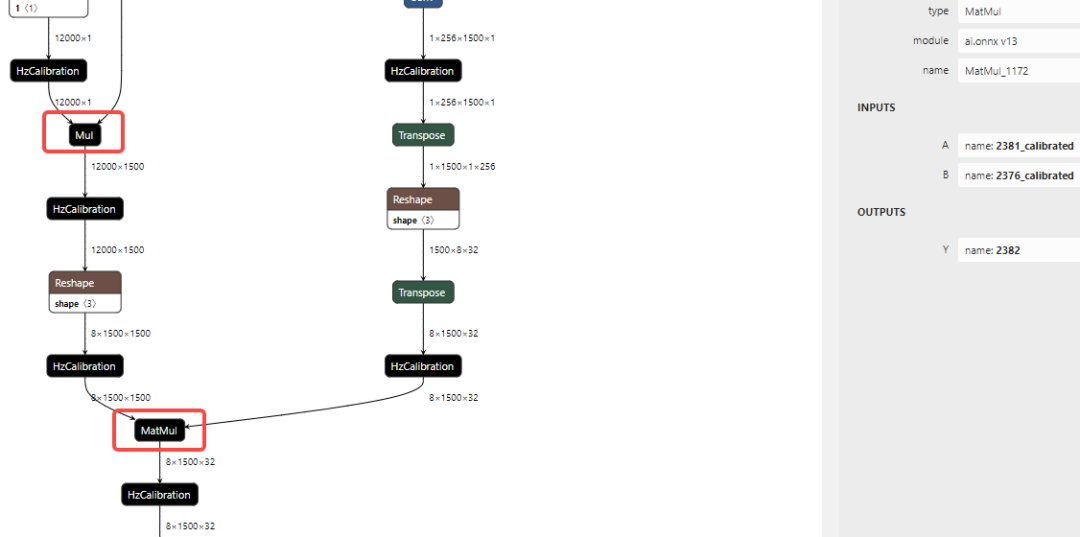
- 标记点 6
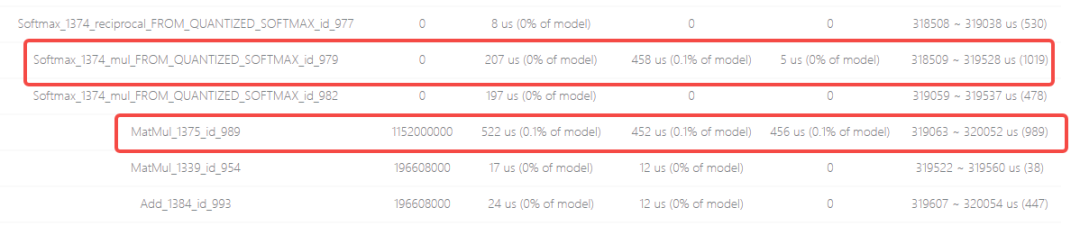
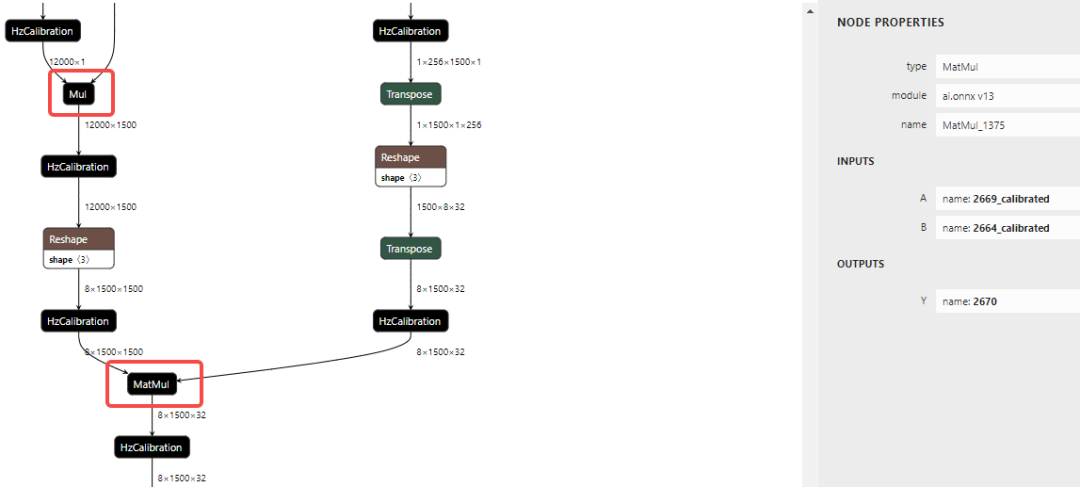
可以看到引起带宽瓶颈的算子的 Softmax_1374、MatMul_1375,onnx 模型中对应的子结构为:
04 初步结论
综合以上分析结果可知,此模型中引起性能问题的是 Softmax 和 MatMul 算子组成的子结构,在下一篇文章中,我们将介绍模型性能相关的优化策略。

加入社区
更多推荐



 28
28 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)