
地平线 3D 目标检测 bev_sparse 参考算法-V1.0
在自动驾驶视觉感知系统中,为了获得环绕车辆范围的感知结果,通常需要融合多摄像头的感知结果。目前更加主流的感知架构则是选择在特征层面进行多摄像头融合。
该示例为参考算法,仅作为在 征程 6 上模型部署的设计参考,非量产算法
01 简介
在自动驾驶视觉感知系统中,为了获得环绕车辆范围的感知结果,通常需要融合多摄像头的感知结果。目前更加主流的感知架构则是选择在特征层面进行多摄像头融合。
其中比较有代表性的路线就是这两年很火的 BEV 方法,继 Tesla Open AI Day 公布其 BEV 感知算法之后,相关研究层出不穷,感知效果取得了显著提升,BEV 也几乎成为了多传感器特征融合的代名词。
但是,随着大家对 BEV 研究和部署的深入,BEV 范式也逐渐暴露出来了一些缺陷:
-
感知范围、感知精度、计算效率难平衡:从图像空间到 BEV 空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及 BEV 特征图尺寸成正相关。
在大家常用的 nuScenes 数据中,感知范围通常是长宽 [-50m, +50m] 的方形区域,然而在实际场景中,我们通常需要达到单向 100m,甚至 200m 的感知距离。
若要保持 BEV Grid 的分辨率不变,则需要大大增加 BEV 特征图的尺寸,从而使得端上计算负担和带宽负担都过重;若保持 BEV 特征图的尺寸不变,则需要使用更粗的 BEV Grid,感知精度就会下降。
因此,在车端有限的算力条件下,BEV 方案通常难以实现远距离感知和高分辨率特征的平衡;
-
无法直接完成图像域的 2D 感知任务:BEV 空间可以看作是压缩了高度信息的 3D 空间,这使得 BEV 范式的方法难以直接完成 2D 相关的任务,如标志牌和红绿灯检测等,感知系统中仍然要保留图像域的感知模型。
实际上,我们感兴趣的目标(如动态目标和车道线)在空间中的分布通常很稀疏,BEV 范式中有大量的计算都被浪费了。因此,我们希望实现一个高性能高效率的长时序纯稀疏融合感知算法,一方面能加速 2D->3D 的转换效率,另外一方面在图像空间直接捕获目标跨摄像头的关联关系更加容易,因为在 2D->BEV 的环节不可避免存在大量信息丢失。
地平线提出了 Sparse4D 及其进化版本 Sparse4D v2,从 Query 构建方式、特征采样方式、特征融合方式、时序融合方式等多个方面提升了模型的效果。
02 性能精度指标

03 公版模型介绍
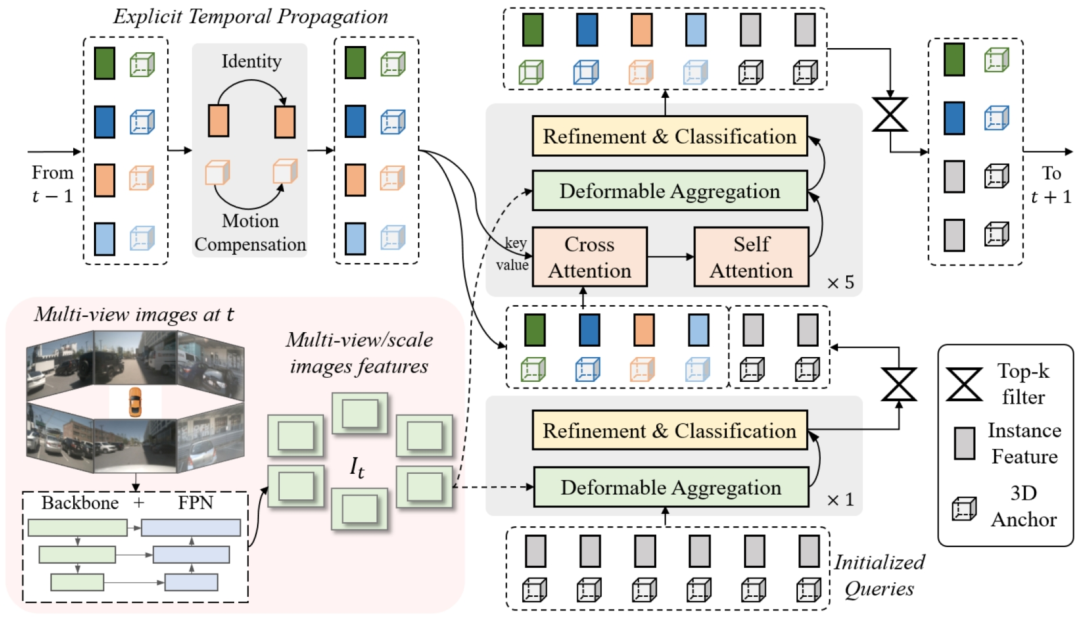
Sparse4D 采用了 Encoder-Decoder 结构。其中 Encoder 包括 image backbone 和 neck,用于对多视角图像进行特征提取,得到多视角多尺度特征图。
同时会 cache 历史帧的图像特征,用于在 decoder 中提取时序特征;Decoder 为多层级联形式,输入时序多尺度图像特征图和初始化 instance,输出精细化后的 instance,每层 decoder 包含 self-attention、deformable aggregation 和 refine module 三个主要部分。
学习 2D 检测领域 DETR 改进的经验,我们也重新引入了 Anchor 的使用,并将待感知的目标定义为 instance,每个 instance 主要由两个部分构成:
-
Instance feature :目标的高维特征,在 decoder 中不断由来自于图像特征的采样特征所更新;
-
3D Anchor :目标结构化的状态信息,比如 3D 检测中的目标 3D 框(x, y, z, w, l, h, yaw, vx, vy);公版通过 kmeans 算法来对 anchor 的中心点分布进行初始化;
同时,在网络中会基于一个 MLP 网络来对 anchor 的结构化状态进行高维空间映射得到 Anchor Embed 𝐸 ,并与 instance feature 相融合。
基于以上定义,通过初始化一系列 instance,经过每一层 decoder 都会对 instance 进行调整,包括 instance feature 的更新,和 anchor 的 refine。基于每个 instance 最终预测的 bounding box。
04 地平线部署说明
公版 sparse4d 在 征程 6 上部署的改动点为:
-
一阶段生成的 featuremap 只使用 FPN 的第二层(stride=16),非公版的使用 4 层。
-
DeformableFeatureAggregation 中 kps_generator 直接使用 offset(linear)生成,非公版的基于 anchor 生成。
-
RefinementModule 对速度没有做 refine 计算,公版使用了。
下面将部署优化对应的改动点以及量化配置依次说明。
4.1 性能优化
改动点 1:
一阶段生成的 featuremap 只使用 FPN 的 1 层(公版使用 4 层),通过实验验证 level_index=2(stride=16)时精度和性能平衡的更好。
neck=dict(
type="FixFPN",
in_strides=[2, 4, 8, 16, 32],
in_channels=[256, 256, 512, 1024, 2048],
fix_out_channel=256,
out_strides=[4, 8, 16, 32],
),
head=dict(
type="SparseBEVOEHead",
enable_dn=True,
level_index=[2],
cls_threshold_to_reg=0.05,
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/head.py
if self.level_index is not None:
feature_maps_head = []
for index in self.level_index:
if compiler_model is False:
feature_maps_head.append(feature_maps[index].float())
else:
feature_maps_head.append(feature_maps[index])
feature_maps = feature_maps_head
batch_size = feature_maps[0].shape[0] // self.num_views
改动点 2:
- DeformableFeatureAggregation 中 kps_generator 直接使用 offset(linear)生成,非公版的基于 anchor 生成。(公版的方式会导致延迟增加)。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/det3d_blocks.py
SparseBEVOEKeyPointsGenerator
def __init__(
self,
embed_dims=256,
num_pts=13,
):
self.offset = nn.Linear(self.embed_dims, self.num_pts * 3)
self.keypoints_add = FloatFunctional()
def forward(
self,
anchor,
instance_feature,
):
bs, num_anchor = anchor.shape[:2]
key_points = self.offset(instance_feature).view(
bs, num_anchor, self.num_pts, 3
)
key_points = self.keypoints_add.add(key_points, anchor[..., None, 0:3])
return key_points
改动点 3:
RefinementModule 的 velocity 没有 refine。经过实验公版的 vx 的 refine 对精度影响较小,基于性能考虑去除该操作。
def forward(
self,
instance_feature,
anchor,
anchor_embed,
return_cls=True,
):
feature = self.add1.add(instance_feature, anchor_embed)
output = self.layers(feature)
output = self.add2.add(output, anchor)
#公版实现:
# if self.output_dim > 8:
# if not isinstance(time_interval, torch.Tensor):
# time_interval = instance_feature.new_tensor(time_interval)
# translation = torch.transpose(output[..., VX:], 0, -1)
# velocity = torch.transpose(translation / time_interval, 0, -1)
# output[..., VX:] = velocity + anchor[..., VX:]
if return_cls:
assert self.with_cls_branch, "Without classification layers !!!"
cls = self.cls_layers(instance_feature)
else:
cls = None
if return_cls and self.with_quality_estimation:
quality = self.quality_layers(feature)
else:
quality = None
return output, cls, quality
4.2 精度优化
4.2.1 量化精度
为量化精度保证,我们将以下的算子配置为 int16 或 int32 输出:
- temp_interaction、interaction 操作中对输出的 instance_featuremap 使用固定 scale 的 int16 量化
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/head.py
注:fix_Scale 不同的数据集数据范围不同,需要根据私有数据集的数据范围固定,scale 计算方式为:输入的最值的绝对值除以 2 的 n-1 次幂(n 为量化位数)
self.fc_after.qconfig = get_default_qat_qconfig(
dtype="qint16",
activation_qkwargs={
"observer": FixedScaleObserver,
"scale": 50 / QINT16_MAX,
},
)
- anchor_embed 时对生成的 anchor 使用 int16 量化,其中 instance_bank 的 anchor 的 update 更新中有多个 op 需要使用 int16 保障精度:
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/instance_bank.py
self.anchor_quant_stub.qconfig = qconfig_manager.get_qconfig(
activation_qat_qkwargs={"dtype": qint16, "averaging_constant": 0},
activation_calibration_qkwargs={
"dtype": qint16,
},
weight_qat_qkwargs={
"averaging_constant": 1,
},
)
def set_qconfig(self) -> None:
"""Set the qconfig."""
from horizon_plugin_pytorch.dtype import qint16
from hat.utils import qconfig_manager
self.anchor_cat.qconfig = qconfig_manager.get_qconfig(
activation_qat_qkwargs={"dtype": qint16, "averaging_constant": 0},
activation_calibration_qkwargs={
"dtype": qint16,
},
weight_qat_qkwargs={
"averaging_constant": 1,
},
)
self.anchor_where.qconfig = qconfig_manager.get_qconfig(
...
)
self.temp_anchor_quant_stub.qconfig = qconfig_manager.get_qconfig(
...
)
- KeyPointsGenerator:key_points 的生成中对 offset、keypoints_add 做 int16 量化。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/det3d_blocks.py
self.offset.qconfig = qconfig_manager.get_qconfig(
activation_qat_qkwargs={"dtype": qint16, "averaging_constant": 0},
weight_qat_qkwargs={
"averaging_constant": 1,
},
activation_calibration_qkwargs={
"dtype": qint16,
},
)
self.keypoints_add.qconfig = qconfig_manager.get_qconfig(
...
)
- RefinementModule:对中间的 add 层和输出层做 int16 和 int32 的输出(注意 cache 不能 int32 输出,还需输入给下一帧)
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/det3d_blocks.py
self.layers[-1].qconfig = qconfig_manager.get_qconfig(
activation_qat_qkwargs={"dtype": qint16, "averaging_constant": 0},
activation_calibration_qkwargs={
"dtype": qint16,
},
weight_qat_qkwargs={
"averaging_constant": 1,
},
)
self.add2.qconfig = qconfig_manager.get_qconfig(
...
)
if self.with_cls_branch is True:
self.cls_layers[-1].qconfig = qconfig_manager.get_qconfig(
...
)
if self.with_quality_estimation is True:
self.quality_layers[
-1
].qconfig = qconfig_manager.get_default_qat_out_qconfig()
- DeformableFeatureAggregation:对 point 做固定 scale 和 int16 量化。
/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/sparsebevoe/blocks.py
注:fix_Scale 不同的数据集数据范围不同,需要根据私有数据集的数据范围固定,scale 计算方式为:输入的最值的绝对值除以 2 的 n-1 次幂(n 为量化位数)
self.point_quant_stub.qconfig = qconfig_manager.get_qconfig(
activation_qat_qkwargs={"dtype": qint16, "averaging_constant": 0},
weight_qat_qkwargs={
"averaging_constant": 1,
},
activation_calibration_qkwargs={
"dtype": qint16,
},
)
self.point_cat.qconfig = qconfig_manager.get_qconfig(
...
)
self.point_matmul.qconfig = get_default_qat_qconfig(
dtype="qint16",
activation_qkwargs={
"observer": FixedScaleObserver,
"scale": 60 / QINT16_MAX,
},
)
self.reciprocal_op.qconfig = get_default_qat_qconfig(
...
)
self.point_mul.qconfig = get_default_qat_qconfig(
...
)
05 总结与建议
5.1 部署建议
-
性能:可以使用单层 feature 来做特征提取,根据精度和性能表现选择某层 stride 特征。
-
对精度影响较小但是对性能提升较大或量化损失较大的层可以选择性的裁剪。
-
可以尝试 decoder_layers、num_points、num_anchor、不同 stride 层裁剪对精度的影响来找到符合预期的配置。
-
对 points 相关的计算(anchor_projection、project_points、key_points 计算)建议开启 int16 和手动固定 scale 的方式。
-
使用精度 debug 工具、敏感度分析工具来降低量化损失
本文通过对 SparseBevOE 在地平线征程 6 上量化部署的优化,使得模型在该计算方案上用低于 2%的量化精度损失(仍在优化中),得到 latency 为 36ms 的部署性能,同时,通过 SparseBevOE 的部署经验,可以推广到其他模型部署优化,例如包含使用稀疏 BEV 的模型部署。
06 附录
-
论文:https://arxiv.org/abs/2311.11722
-
公版代码:
https://link.zhihu.com/?target=https%3A//github.com/linxuewu/Sparse4D
-
课程:https://www.shenlanxueyuan.com/open/course/210
-
知乎专栏:https://zhuanlan.zhihu.com/p/637096473

加入社区
更多推荐



 26
26 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)